How Claude Code Actually Remembers Things

I spent a few days reading the leaked Claude Code source, the community write-ups, and the architecture doc I built from both. The system is more layered than any blog post I read about it, and the patterns that show up are worth stealing for any agent harness. Here is the full picture, top to bottom.
Start with the framing
Claude Code does not have a “memory feature.” Memory is the harness.
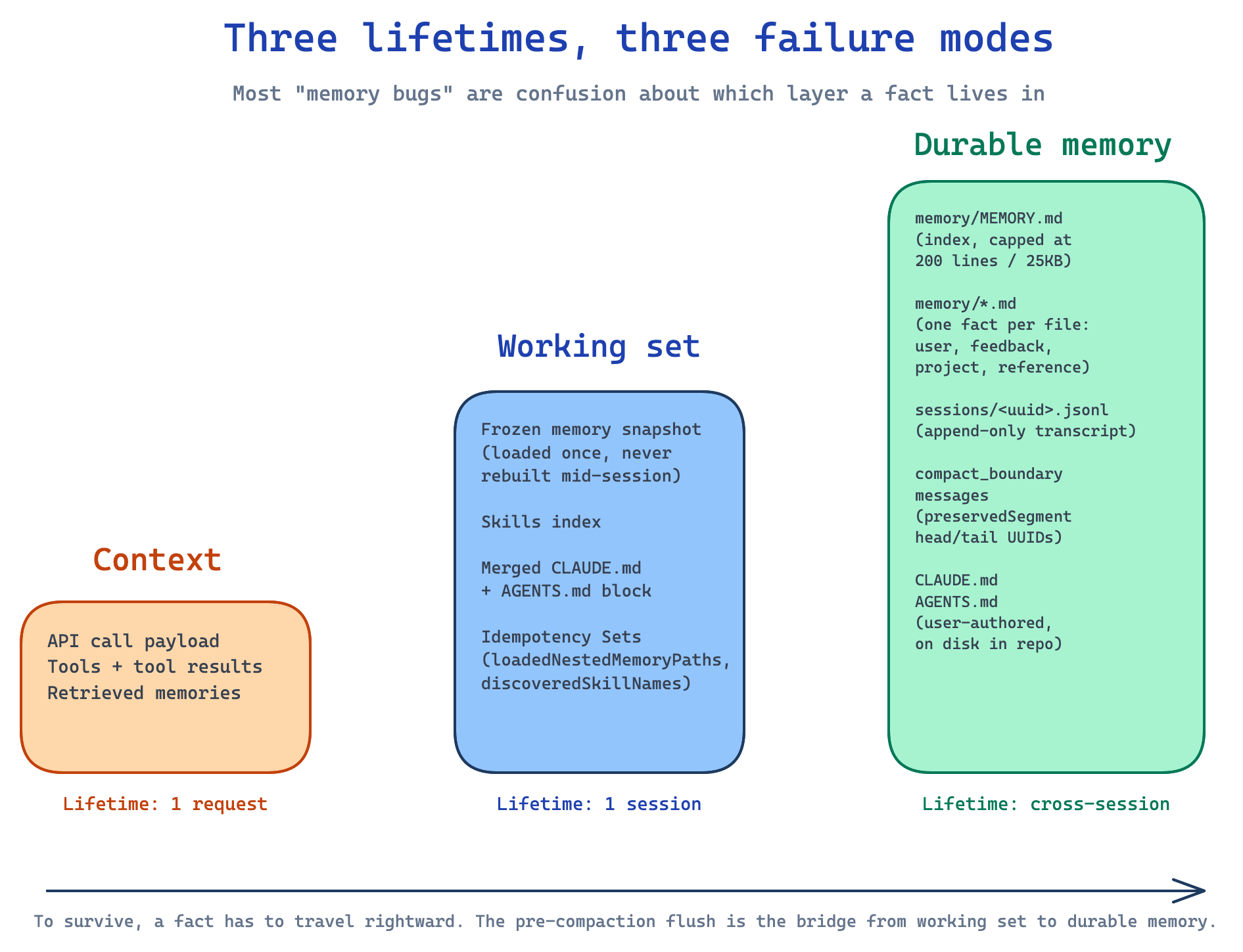
Strip out memory and you do not get a stateless Claude. You get a Claude that cannot operate. Context assembly, prompt caching, compaction, persistence, sub-agent dispatch, telemetry — every layer of the agent loop participates in remembering. Most “memory bugs” people report are not bugs in a memory module. They are confusion between three separate layers:
- Context: everything the model sees on a single API call. Lifetime: one request.
- Working set: the cached snapshot loaded once per session and frozen. Lifetime: one session.
- Durable memory: files on disk, transcripts, compact boundaries that survive process restart. Lifetime: cross-session.
A fact can sit in durable memory but be missing from the working set. Or it can be in the working set, then disappear from context after compaction. Hold on to those three names. They show up in every section below.
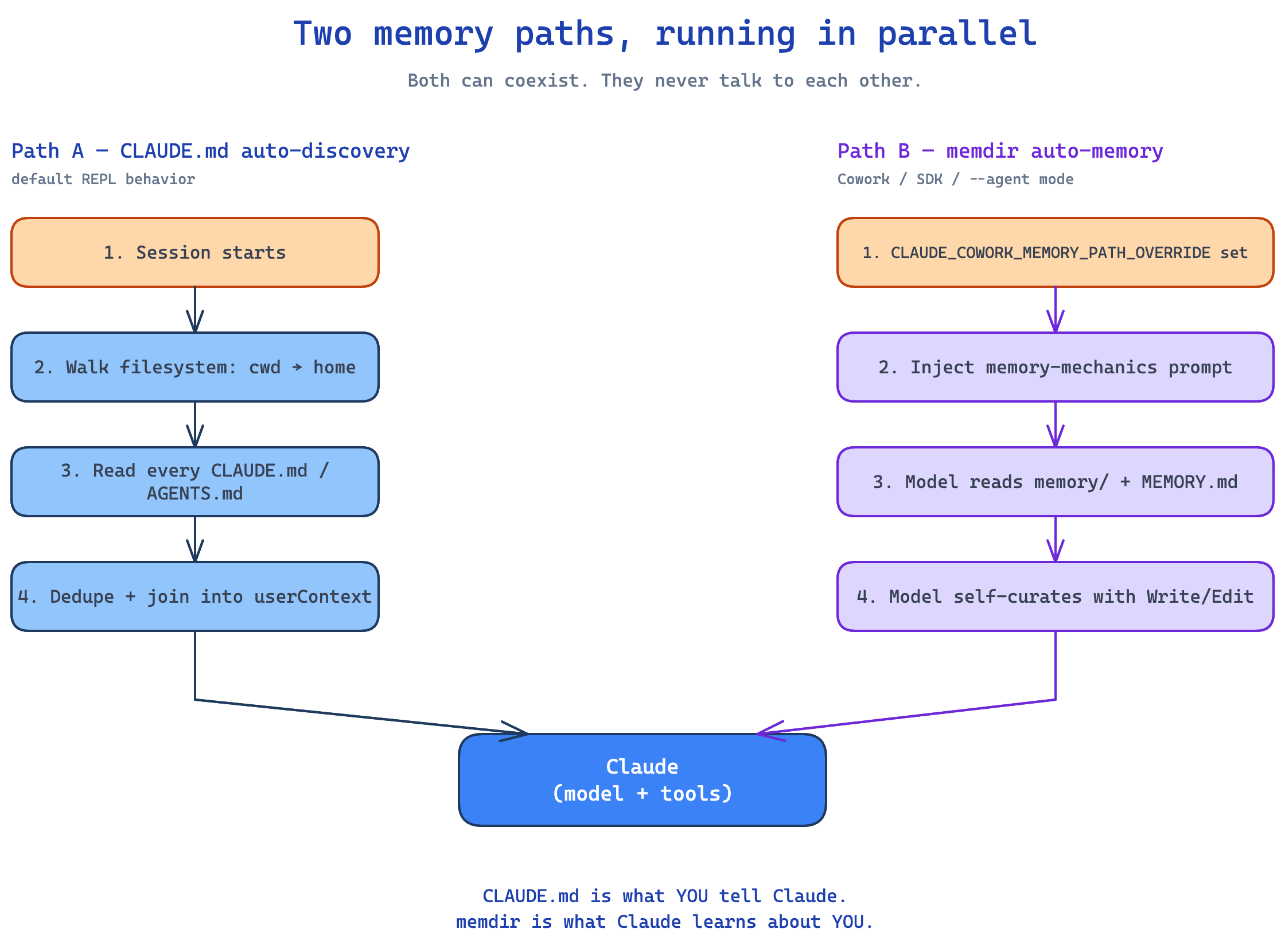
Two memory paths, running in parallel
Claude Code has two memory systems, and they do not talk to each other.
The first is what most people see. On session start, Claude walks the filesystem from your current directory upward, all the way to your home folder. It reads every CLAUDE.md and AGENTS.md it finds. Files are deduplicated, expanded for @-imports (one file referencing another), and joined into a userContext block that is memoized for the session. This is what makes Claude “feel like” it knows your repo. You commit a CLAUDE.md and every contributor’s Claude reads it. The team gets the same context for free. This path is enabled by default. It is only disabled by CLAUDE_CODE_DISABLE_CLAUDE_MDS or --bare.
The second path is for Cowork, SDK callers, and --agent mode. When the env var CLAUDE_COWORK_MEMORY_PATH_OVERRIDE is set, Claude is given a “memory mechanics” prompt that tells it: you have a memory directory at this path, the index is MEMORY.md, here are the four types of memory you can write, here is when to read and when to forget, files older than one day carry a freshness warning. Claude then uses the normal Write, Edit, and Read tools to manage the directory itself. There is no special memory tool. Memory is just files Claude learned to use.
Both paths can coexist. CLAUDE.md is what you tell Claude. memdir is what Claude learns about you. The --bare flag actually lists both as separable in its kill-set, which confirms the two-path model in the user-facing surface.
What is actually on disk
Everything lives in plain text or JSONL. No vector store, no embeddings, no database. This is intentional. It makes memory inspectable, version-controllable, and recoverable.
1
2
3
4
5
6
7
8
9
~/.claude/projects/<your-repo>/
├── memory/
│ ├── MEMORY.md (index of all memory files)
│ ├── user_role.md (one fact per file)
│ ├── feedback_*.md
│ ├── project_*.md
│ └── reference_*.md
└── sessions/
└── <session-uuid>.jsonl (full transcript, append-only)
Three invariants govern the design.
One fact, one file. Atomic units are easier to update, delete, version, and reason about than blobs.
The index is bounded. MEMORY.md is hard-capped at 200 lines or 25KB, whichever hits first. If you blow past either limit, the bottom silently falls off. Claude does not see truncated entries and does not know to warn you. This is the most-discussed weakness of the design. mem0 sells a vector-store replacement specifically for this reason.
Transcripts are append-only. Every assistant message, user message, and compact-boundary system message is recorded. Pruning is reapplied on load, never stored.
Four memory types, and a longer “do not save” list
Claude can write only four kinds of memory:
- User memories. Role, expertise, preferences, communication style. Slow decay.
- Feedback memories. Corrections, validated approaches, things to avoid. Slow decay.
- Project memories. Deadlines, decisions, in-flight work, motivation. Fast decay.
- Reference memories. Pointers to external systems like Linear, Slack, or dashboards.
The exclusion list matters more than the inclusion list. Claude is told never to save anything you can git log or git blame your way to, no in-progress task state, no debugging recipes, no conversation-bound details. Most “memory rot” is a violation of the exclusion list, not a 200-line problem.
Each memory file carries a freshness warning when its age exceeds one day. The warning is appended to the content before Claude sees it: “This memory is X days old. Memories are point-in-time observations, not live state.” This gives the model an explicit “trust this less” signal. There is one nasty failure mode here. Freshness warnings only fire for memories that load. If a memory falls off the truncated index, it generates no warning. It just disappears.
The read path: how memory enters the prompt
Every API call assembles its context from layers in a fixed order:
1
2
3
4
5
6
7
8
9
10
11
12
[ 0 ] System: agent identity, capabilities, tool definitions
[ 1 ] System: tool-aware behavior guidance
[ 2 ] System: Honcho / cross-platform identity (optional)
[ 3 ] System: developer's custom system prompt
[ 4 ] System: memory-mechanics prompt (memdir path only)
[ 5 ] System: frozen memory snapshot (USER + MEMORY block, capped)
[ 6 ] System: skills index (compact, ~2 tokens per skill)
[ 7 ] System: project context files (CLAUDE.md, AGENTS.md, .cursorrules)
[ 8 ] System: date, time, platform hints
[ 9 ] User context: git status, current date
[10 ] Conversation history (post compact-boundary)
[11 ] Current user message
Layers 0 through 10 are stable across a turn. Layer 11 changes every turn. That ordering is the whole reason for the next pattern.
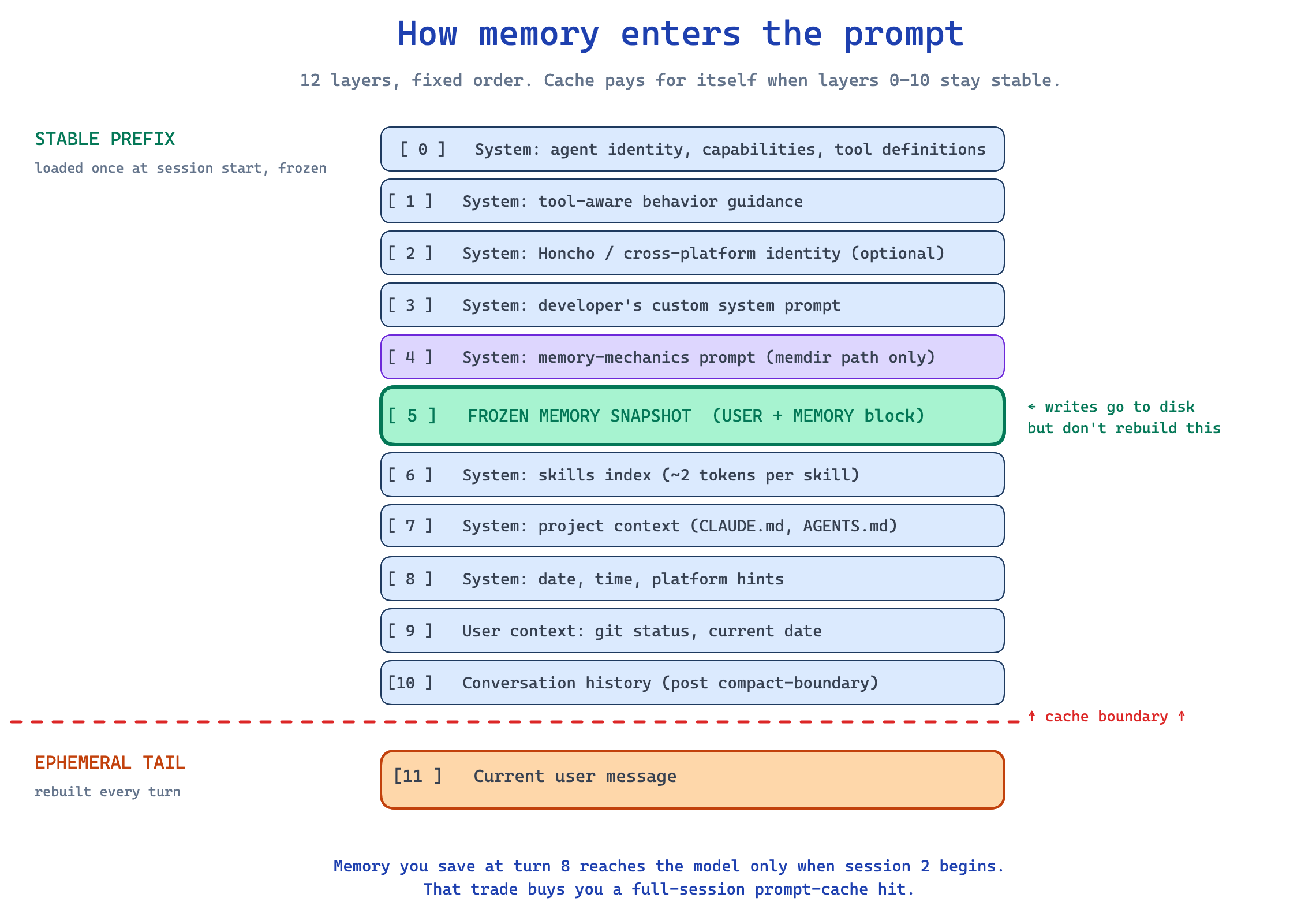
The frozen snapshot pattern
When Claude loads memory at session start, it freezes the snapshot into the system prompt. Mid-session writes go to disk immediately, but the prompt does not rebuild until the next session, or until a post-compaction event triggers a rebuild.
This trades intra-session consistency for a full-session prompt-cache hit. A memory you save at turn 8 will not reach the model until the next session begins.
In practice, this is the right trade. Provider prompt caches have a TTL of a few minutes and reward stability. Mutating the system prompt mid-session would invalidate the cache on every turn and pay full cache-write pricing each time. The frozen snapshot is what makes Claude feel responsive across long sessions instead of getting slower as memory accumulates.
Idempotency guards and async prefetch
Two small details prevent context bloat across many turns.
The query engine carries a loadedNestedMemoryPaths Set that tracks every memory file it has already loaded. When a CLAUDE.md @-imports another file, the import only runs once per conversation, no matter how many parents reference it. A second Set, discoveredSkillNames, tracks which skills have already been announced to the model. Skills are progressively disclosed: the index always sits in the prompt, but full skill content only loads on first use.
Memory retrieval for the current turn fires as a background task at the start of the turn and is awaited only after tool execution completes. The harness deliberately overlaps memory I/O with model streaming and tool calls. The reason is in the source comments: in production telemetry, 97% of memory-relevance lookups returned nothing. Blocking the critical path on a 97%-miss-rate operation is a clear loss. Backgrounding it is free.
Three ways memory gets written
Writes happen in three modes, in increasing order of automation.
First mode is explicit user request. You say “remember that,” the model picks the type, drafts the entry, and uses Write to create a memory file plus an index entry.
Second mode is agent-initiated during the session. The model recognizes a signal worth keeping (a preference, a correction, a recurring pattern) and writes proactively. The write hits disk. The prompt does not rebuild because of the frozen snapshot rule. The new memory becomes visible at the next session start.
Third mode is the background extractor. After the session ends, a separate extract-memories agent reads the transcript, pulls atomic facts, classifies them by type, deduplicates against existing memory, and writes new entries. This is gated behind feature flags (EXTRACT_MEMORIES, tengu_passport_quail) and not on for everyone yet.
Between modes 2 and 3 sits the most important moment in the whole architecture: the pre-compaction flush.
The pre-compaction flush
Before the harness summarizes a long conversation (which is lossy), it injects a synthetic system message that tells the model: this session is being compressed, save anything worth remembering, prioritize user preferences and recurring patterns over task-specific details. The model gets one extra API call with only the memory tool available and decides what to persist.
This pattern turns compaction from pure loss into a consolidation event. Without it, every long session leaks knowledge. With it, the most important facts cross the boundary and live in durable memory. It is the single best pattern in the whole architecture, and most agent systems do not have anything like it.
Every write is also scanned for prompt-injection markers, credential exfiltration strings, SSH backdoor hints, and invisible Unicode characters. Memory persists across sessions, so a poisoned write becomes a persistent attack surface. Defense at the write boundary is mandatory.
The five-stage compaction pipeline
This is the part nobody else describes correctly. Every turn, before sending to the API, Claude runs a compaction pipeline. Five stages, ordered cheap to expensive:
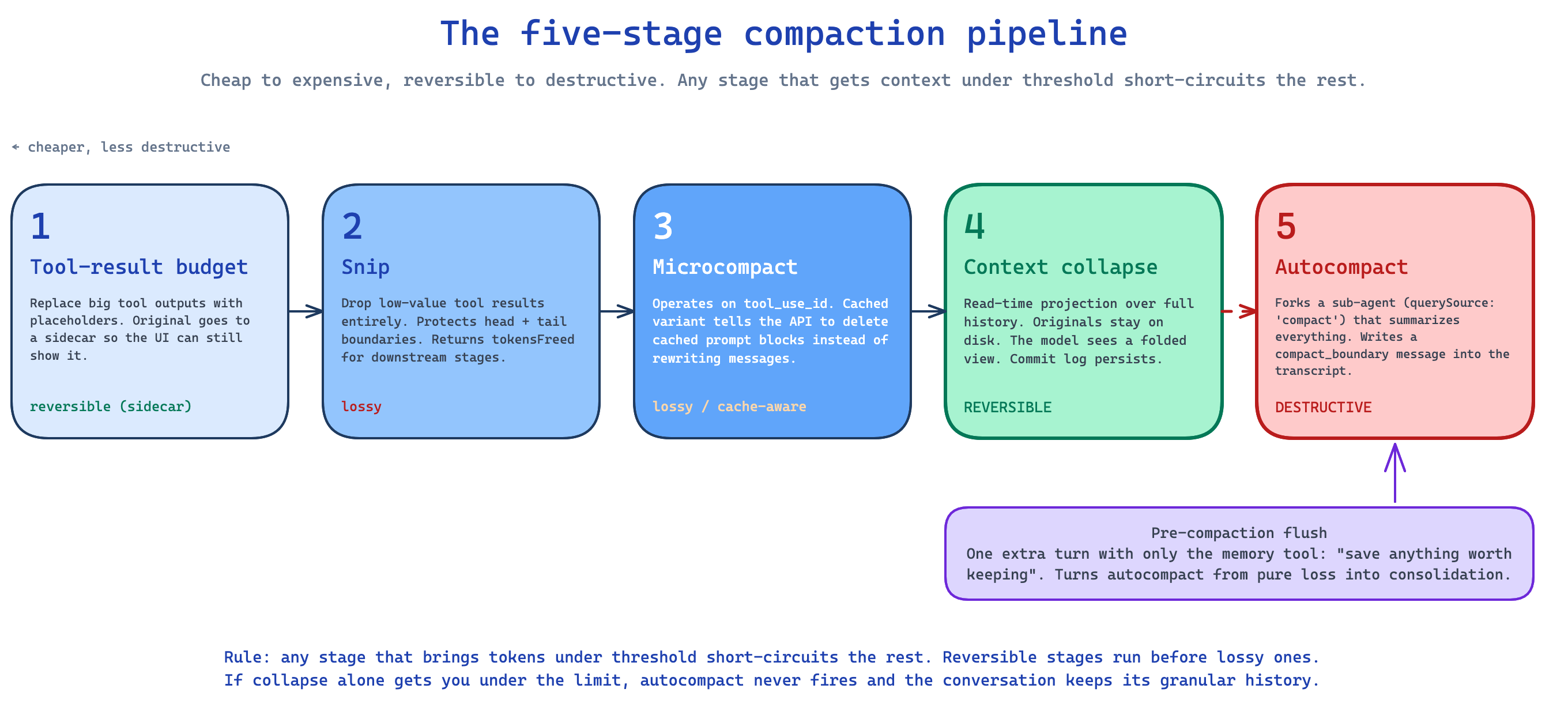
Per-message tool-result budget. Each tool can declare a max output size. Tools without one share a per-message budget. When a tool’s output exceeds the cap, its body is replaced by a placeholder. The original is kept in a sidecar so the UI can still show it. The model sees a trimmed view, the user sees the full output.
Snip. A more aggressive trim. Drops low-value tool results entirely, things like verbose builds, large file dumps, repetitive errors. Protects a head and tail boundary so recent context survives. Yields a
snip_boundarymessage so SDK consumers can replay the snip on their projection store. Snip also returns the number of tokens it freed, and that number is plumbed all the way down to the autocompact threshold check. Without that plumbing, autocompact would fire on stale token estimates and the system would over-compact itself.Microcompact. Operates on tool-use IDs rather than content. Tool calls that are no longer relevant can be pruned without reformatting messages. The cached variant of microcompact does something subtler. Instead of rewriting messages, it tells the API to delete specific cached prompt blocks. This avoids re-paying the cache-write cost on later turns. Boundary messages are deferred and only yielded after the API response, using the actual
cache_deleted_input_tokensfield. The field is cumulative and sticky across requests, so the harness captures a baseline before each request and subtracts to compute the per-request delta.Context collapse. Conceptually different from every other stage. Collapse is read-time projection over the full message history. Original messages stay in storage, the model sees a projected view, summary messages live in a separate collapse store. This makes collapse reversible. The commit log persists across turns. The order rule is critical: collapse runs before autocompact specifically so a successful collapse pre-empts autocompact. If projection alone gets the context under threshold, the conversation keeps its granular history instead of getting summarized.
Autocompact. The lossy summary. Forks a sub-agent with
querySource: 'compact', sends it the full pre-compact context, and asks for a summary. The summary plus preserved attachments and hook results becomes the new conversation array. Acompact_boundarysystem message is inserted withpreservedSegment.{headUuid, tailUuid}so resume can prune correctly later.
The big idea: reversible stages run before destructive ones. If projection alone gets you under the limit, autocompact never fires and the conversation keeps its granular history. Every other harness I have read jumps straight to “summarize when full,” and you can feel the difference.
After autocompact, every subsequent turn fires a tengu_post_autocompact_turn event with an incrementing counter. This is how Anthropic measures recovery quality. If conversations consistently die within 1 to 2 turns post-compact, the summary dropped something critical and the team can see it in the data.
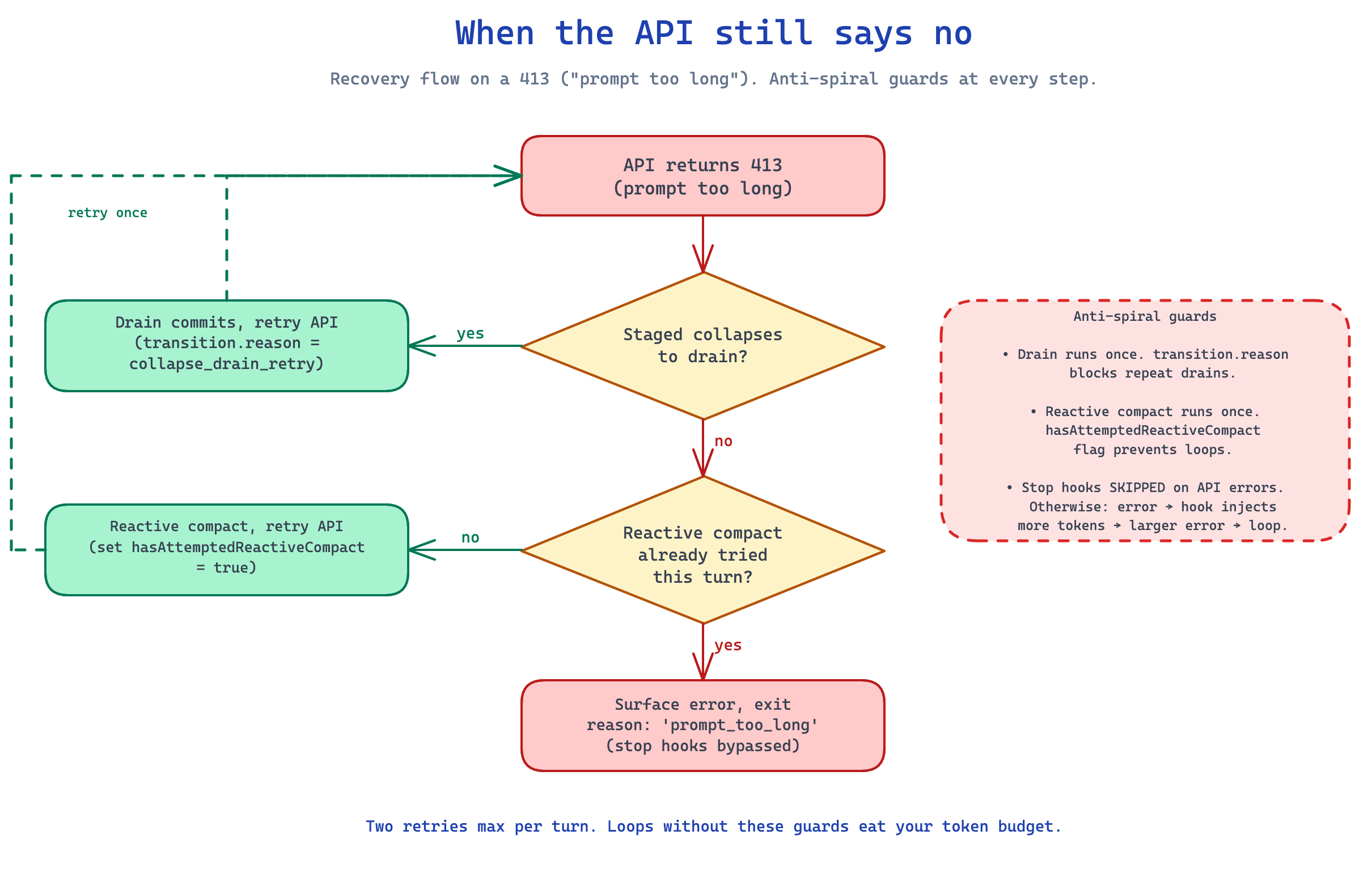
When the API still says no
Sometimes all five stages run and the API still returns a 413 (“prompt too long”). The recovery flow runs in order:
First, drain staged context-collapses. If commits are pending, force them and retry.
If that does not free enough room, try a reactive compact. This is a forked sub-agent that summarizes with cache-safe params, returns post-compact messages, and the loop retries the API.
If reactive compact also fails, surface the error and exit with reason: 'prompt_too_long'.
Anti-spiral guards exist at every step. A transition.reason discriminator prevents drain → drain → drain. hasAttemptedReactiveCompact caps reactive at one attempt per turn. Stop hooks are bypassed on API errors because running them would inject more tokens, fail again, and spiral.
There is also a separate output-token recovery for the case where the response, not the prompt, is too long. It either escalates the cap from 8k to 64k once, or injects a continuation message: “Output token limit hit. Resume directly, no apology, no recap. Pick up mid-thought if that is where the cut happened. Break remaining work into smaller pieces.” That instruction text alone tells you a lot about how Anthropic thinks about prompt economy.
Persistence and resume
Every assistant message, user message, and compact_boundary system message is recorded to a per-session JSONL transcript. Assistant messages are fire-and-forget; user messages and boundaries are awaited so they cannot be lost on a kill.
The interesting part is --resume. When you resume a session, the harness does not reload every message. It reads the transcript, finds the most recent compact_boundary, walks the preservedSegment.tailUuid backward to verify the linked range, and prunes everything pre-boundary. The full transcript stays on disk for UI scrollback and debugging, the in-memory message array reflects the post-boundary view.
This means compaction is durable. A session that compacted at turn 50 starts back at roughly turn 10 of context on resume, not turn 50. It also means mid-write crashes are tolerated: if the SDK process is killed before the tail UUID is written, the relink walk fails and the system falls back to loading the full pre-compact history. Defensive fallback rather than corruption.
Background work between sessions
Real consolidation happens after the session ends.
The extract-memories agent reads the transcript and pulls atomic facts. The session-memory service is a sub-agent that owns memory operations during compaction. The team-memory-sync service splits memories into private and team-shared when the TEAMMEM flag is on. The auto-dream service, named after biological sleep, walks the memory directory between sessions, merges duplicates, ages out stale entries, and produces a cleaner index for the next session.
This separation matters. Synchronous extraction during the session catches the obvious facts. Asynchronous consolidation between sessions does the work the synchronous loop cannot: walk the full memory directory, identify duplicates and contradictions, merge them, prune stale entries. Without it, memory directories accumulate ten phrasings of the same fact and slowly turn into noise.
How quality is measured
Memory and compaction systems are notorious for failing silently. Claude Code instruments aggressively to make failures visible. Every event includes a queryChainId and queryDepth. That means analytics can answer questions like: in sessions where compaction fired at depth 3, what is the distribution of tengu_post_autocompact_turn.turnCounter? Do conversations that compact more than twice show higher abandonment? What is the cache-hit rate on the compaction call itself across model versions?
Quality is not “did compaction complete.” It is “did the model recover and stay productive afterwards.” Without telemetry that joins across compaction boundaries, you cannot tell whether your memory system is helping or hurting. You are flying blind.
What I would copy
If you are designing a memory system for your own agent, here is what I would steal.
Keep memory as plain text on disk. It stays inspectable, version-controllable, and recoverable. A vector store may come later, but the source of truth should be readable by humans.
Use frozen snapshots. Write to disk immediately, but only rebuild the prompt at session start or post-compaction. Caching pays you back the consistency you give up.
Pipeline your compaction. Order stages cheap to expensive, reversible to destructive. Run a reversible projection before any lossy summary. Plumb the tokens-freed counter through every threshold check downstream so stages do not fight each other on stale numbers.
Run a pre-compaction flush. Give the model one turn to save anything worth remembering before you summarize. This single pattern fixes the worst failure mode of every other memory system I have looked at.
Fork sub-agents for compaction itself, with reserved query sources that bypass blocking-limit checks. The agent that compacts has its own context budget and will deadlock if you treat it like a normal user request.
Wire telemetry that joins across compaction boundaries. Without it, you cannot tell whether your system is helping.
The 200-line cap is not on this list.
What is missing
Reading the source map gives you the architecture but not all the dials. Things I still do not have a confident answer for: the exact protected head and tail counts inside snip, the selection algorithm microcompact uses to pick what to evict, the autocompact prompt template the forked sub-agent runs with, the staging policy context-collapse uses to decide what to fold and when to commit. These all live in modules that were named in the leaked source map but whose contents were not published.
Some of those will leak in the next dump. Some will get reverse-engineered through behavior. The architecture is the part that lasts, and the architecture is what is worth learning.
If I had to summarize the whole system in one line: Claude Code treats memory as a pipeline, not a store. The store is boring on purpose. The pipeline is where the engineering is.