Word2Vec From Scratch A Complete Mathematical and Implementation Guide
 A comprehensive guide that builds understanding from first principles
A comprehensive guide that builds understanding from first principles
Table of Contents
- The Problem: Why Do We Need Word Embeddings?
- The Big Idea: Learning From Context
- Building Intuition: A Simple Example
- The Neural Network Architecture
- Mathematical Foundation
- Why This Approach Works: The Geometric Intuition
- Implementation Walkthrough
- Testing and Results
The Problem: Why Do We Need Word Embeddings?
Imagine you’re building a system to understand whether movie reviews are positive or negative. You encounter these sentences:
- “This movie is fantastic!”
- “This movie is excellent!”
- “This movie is terrible!”
The Traditional Approach Falls Short
In traditional NLP, each word becomes a one-hot vector:
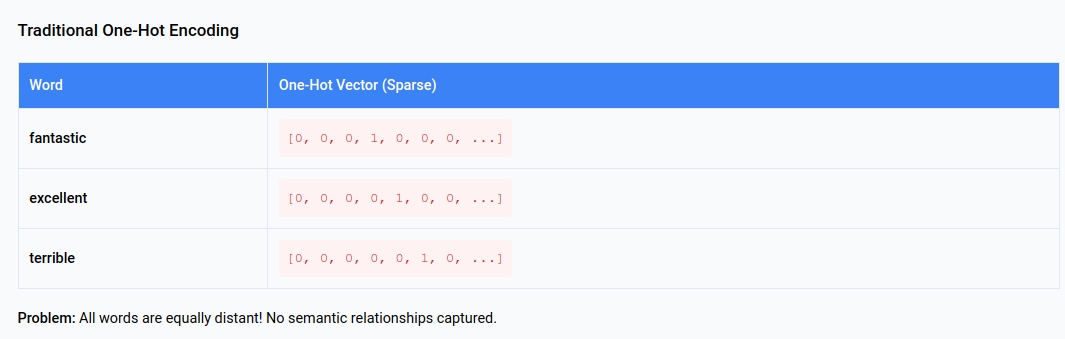
The problem: These vectors tell us nothing about relationships! “Fantastic” and “excellent” are equally distant from each other as “fantastic” and “terrible” - but we know this isn’t right.
What We Really Want
We want vectors that capture meaning:

Now “fantastic” and “excellent” are close in vector space, while “terrible” is far away. This captures semantic meaning!
The Big Idea: Learning From Context
Word2Vec is based on a simple but powerful insight:
“You shall know a word by the company it keeps” - J.R. Firth
Words that appear in similar contexts tend to have similar meanings. Consider:
- “The cat sat on the mat”
- “The dog ran in the park”
- “A kitten played with yarn”
Words like “cat,” “dog,” and “kitten” appear with similar surrounding words (articles, verbs, prepositions). This suggests they’re semantically related.
The Skip-Gram Approach
Instead of trying to define word meanings directly, we’ll train a model to:
Given a word, predict what words are likely to appear around it
If our model learns that “cat” often predicts “sat,” “mat,” “purr,” “meow,” and “dog” often predicts “ran,” “bark,” “fetch,” “play,” then the internal representations of “cat” and “dog” will naturally become similar (since they both predict action words) yet distinct (since they predict different specific actions).
Building Intuition: A Simple Example
Let’s work through a concrete example to build intuition before diving into the math.
Our Training Sentence
1
"The cat sits on the mat"
Step 1: Creating Training Pairs
With a window size of 1 (looking 1 word before and after), we create these training pairs:
| Center Word | Context Words |
|---|---|
| cat | the, sits |
| sits | cat, on |
| on | sits, the |
| the | on, mat |
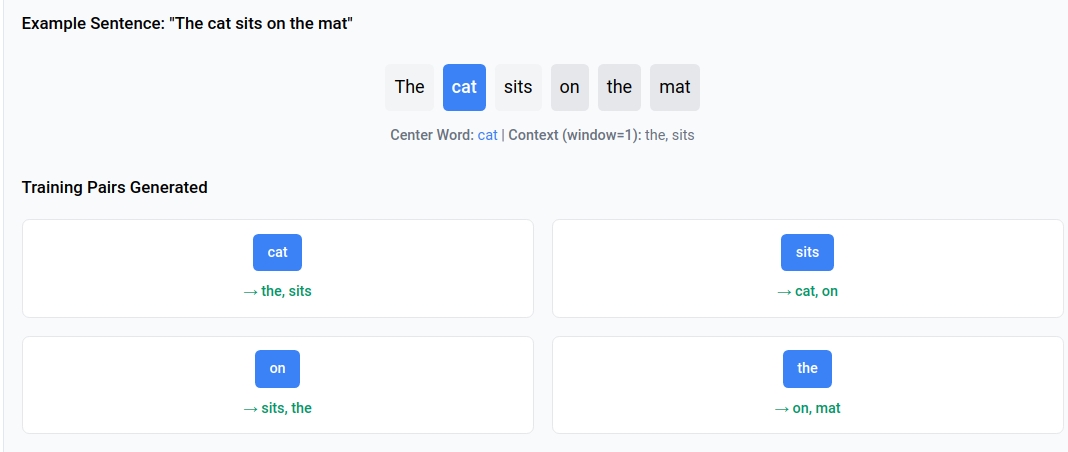
Why this makes sense: If I say “cat,” you might expect to hear “the” or “sits” nearby. This is what we’re teaching our model.
Step 2: The Model’s Job
Our model has two tasks:
- Learn representations for each word (the embeddings)
- Predict context words given a center word
For example, given “cat,” it should assign high probability to “the” and “sits,” and low probability to unrelated words.
Step 3: The Learning Process
The model starts with random word vectors:
1
2
3
cat = [0.1, -0.3, 0.8] (random initialization)
sits = [0.5, 0.2, -0.1] (random initialization)
the = [-0.2, 0.6, 0.3] (random initialization)
Through training, it adjusts these vectors so that:
catandsitsbecome more similar (they appear together)catand random words become less similar
The Magic Moment
After training, words that appeared in similar contexts will have similar vectors:
1
2
3
4
cat = [0.7, 0.2, -0.4]
kitten = [0.6, 0.3, -0.3] (similar to cat!)
dog = [0.5, 0.1, -0.2] (also similar, but distinct)
car = [-0.1, 0.8, 0.6] (very different - appears with different words)
The Neural Network Architecture
Word2Vec can be viewed as a simple three-layer neural network designed to predict context words from center words (Skip-gram model).
Network Structure
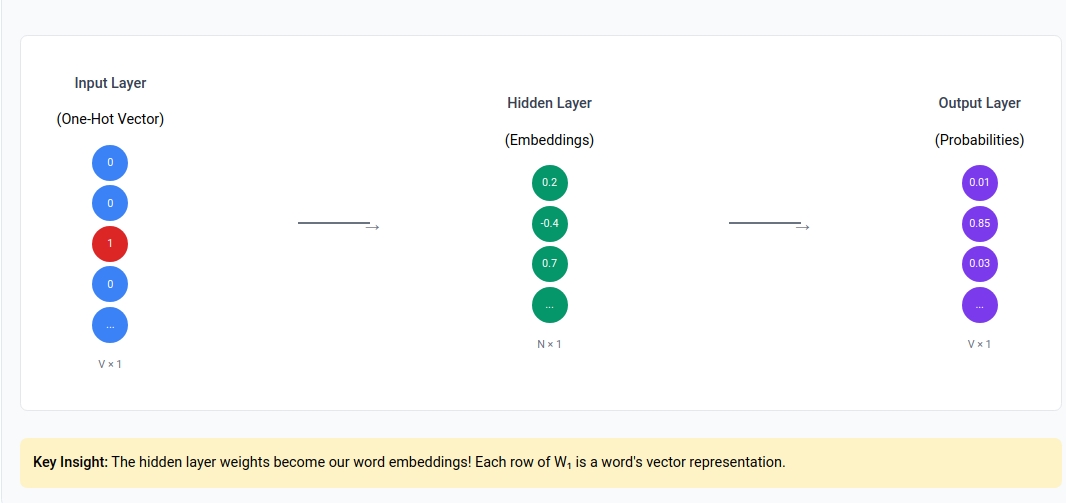
1
2
3
4
5
Input Layer (One-hot) Hidden Layer (Embeddings) Output Layer (Probabilities)
| | |
[0,0,1,0,...] ───────► [0.2,-0.4,0.7,...] ───────► [0.01,0.85,0.03,...]
| | |
V × 1 N × 1 V × 1
Where:
- V = vocabulary size
- N = embedding dimension (typically 100-300)
The Three Layers Explained
Layer 1: Embedding Lookup \(L_1 = XW_1\)
Where:
- $X$ is the one-hot input vector (V × 1)
- $W_1$ is the embedding matrix (V × N)
- $L_1$ is the word embedding (N × 1)
Layer 2: Context Projection
\(L_2 = L_1 W_2\)
Where:
- $W_2$ is the context matrix (N × V)
- $L_2$ is the raw scores for each vocabulary word (V × 1)
Layer 3: Probability Distribution \(L_3 = \text{softmax}(L_2)\)
Key Insight: Embeddings as Lookup
Since $X$ is one-hot encoded, the matrix multiplication $XW_1$ is equivalent to selecting a row from $W_1$:
1
2
3
# If X = [0, 0, 1, 0, 0] (word at index 2)
# Then XW₁ simply returns row 2 of W₁
embedding = W1[word_index, :] # This is the embedding lookup!
This is why the rows of $W_1$ become our final word embeddings.
Mathematical Foundation
The Skip-Gram Objective
For a center word $w_c$ and context word $w_o$, we want to maximize:
\[P(w_o | w_c) = \frac{\exp(\mathbf{u}_{w_c}^T \mathbf{v}_{w_o})}{\sum_{w=1}^V \exp(\mathbf{u}_{w_c}^T \mathbf{v}_w)}\]Notation Breakdown:
- $\mathbf{u}_{w_c}$: embedding of center word $w_c$ (from $W_1$)
- $\mathbf{v}_{w_o}$: context vector of word $w_o$ (from $W_2$)
- $V$: vocabulary size
- \(\mathbf{u}_{w_c}^T \mathbf{v}_{w_o}\)
- dot product measuring similarity

The Complete Forward Pass
Let $A = XW_1W_2$ be the final scores. The objective function becomes:
\[\mathcal{L} = -\sum_{i,j} A_{ij} Y_{ij} + \sum_i \log\left(\sum_k \exp(A_{ik})\right)\]Notation Breakdown:
- $A_{ij}$: score for word $j$ given center word $i$
- $Y_{ij}$: 1 if word $j$ is in context of word $i$, 0 otherwise
- First term: rewards correct predictions
- Second term: normalizes to create probability distribution
Gradient Derivation
The gradient with respect to the scores $A$ is:
\[\frac{\partial \mathcal{L}}{\partial A} = -Y + \sigma(A)\]Where $\sigma(A)$ is the softmax of $A$.
Why this makes sense:
- $Y$: what we want (target distribution)
- $\sigma(A)$: what we predict (current distribution)
- Gradient pushes predictions toward targets
The weight gradients follow from chain rule:
\[\frac{\partial \mathcal{L}}{\partial W_1} = X^T \left(\frac{\partial \mathcal{L}}{\partial A}\right) W_2^T\] \[\frac{\partial \mathcal{L}}{\partial W_2} = (XW_1)^T \left(\frac{\partial \mathcal{L}}{\partial A}\right)\]Why This Approach Works: The Geometric Intuition
The Vector Space Perspective
Think of word embeddings as points in a high-dimensional space. The training process is like a physical simulation:
- Attractive forces: Words that appear together are pulled closer
- Repulsive forces: Words that don’t appear together are pushed apart
- Equilibrium: After training, similar words cluster together
A 2D Visualization
Imagine our embeddings in 2D space:
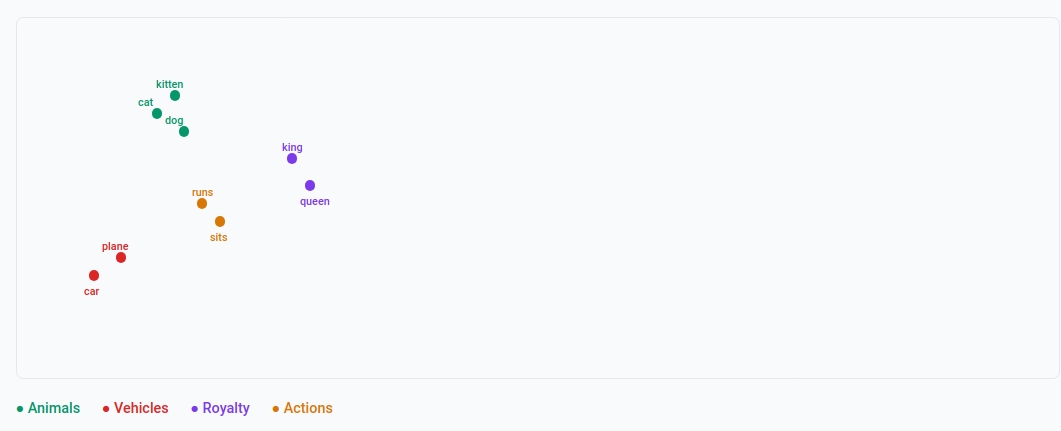
Words like “cat,” “dog,” “puppy” cluster together because they appear in similar contexts. “Car” and “airplane” form their own cluster.
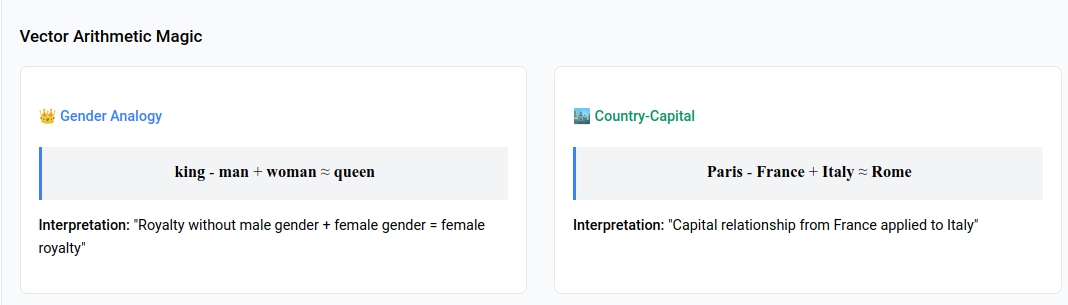
Why Vector Arithmetic Works
The famous example: king - man + woman ≈ queen
This works because:
king - mancaptures the concept of “royalty without gender”- Adding
womangives “female royalty” - The nearest word to this concept is
queen
The vectors encode relationships as directions in the space!
Implementation Walkthrough
Preparing Data
Tokenization
First, we convert raw text into tokens:
1
2
3
4
5
6
7
import re
import numpy as np
from collections import defaultdict
def tokenize(text):
"""Convert text to lowercase tokens"""
return re.findall(r'\b[a-z]+\b', text.lower())
What this does:
\b[a-z]+\b: matches word boundaries containing only letters.lower(): normalizes to lowercase- Returns list of clean tokens
Building Vocabulary
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def build_vocabulary(tokens, min_count=1):
"""Create word-to-index and index-to-word mappings"""
word_counts = defaultdict(int)
# Count word frequencies
for token in tokens:
word_counts[token] += 1
# Filter by minimum count and create mappings
vocab = {}
idx_to_word = {}
# Sort by frequency to ensure consistent ordering
sorted_words = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
idx = 0
for word, count in sorted_words:
if count >= min_count:
vocab[word] = idx
idx_to_word[idx] = word
idx += 1
return vocab, idx_to_word
Step-by-step breakdown:
- Count frequencies:
defaultdict(int)automatically initializes missing keys to 0 - Filter rare words: Only keep words appearing at least
min_counttimes - Create bidirectional mapping:
vocabmaps words to indices,idx_to_wordmaps back
Generating Training Data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def generate_training_pairs(tokens, vocab, window_size=2):
"""Create (center_word, context_word) pairs for training"""
pairs = []
for i, center_word in enumerate(tokens):
if center_word not in vocab:
continue
# Define context window bounds
start = max(0, i - window_size)
end = min(len(tokens), i + window_size + 1)
# Collect context words
for j in range(start, end):
if i != j and tokens[j] in vocab:
center_idx = vocab[center_word]
context_idx = vocab[tokens[j]]
pairs.append((center_idx, context_idx))
return pairs
Mathematical intuition:
- For sentence “the cat sits on mat” with window_size=2
- Center word “cat” (position 1) sees context words at positions [0,2] = [“the”, “sits”]
- This creates pairs: (cat, the), (cat, sits)
The Embedding Model
1
2
3
4
5
6
7
8
9
10
11
class Word2Vec:
def __init__(self, vocab_size, embedding_dim=100):
"""Initialize embedding matrices"""
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
# W₁: Input embeddings (V × N) - Xavier initialization
self.W1 = np.random.normal(0, 0.1, (vocab_size, embedding_dim))
# W₂: Output embeddings (N × V) - Xavier initialization
self.W2 = np.random.normal(0, 0.1, (embedding_dim, vocab_size))
Why two matrices?
- $W_1$: represents words as centers (what context do they predict?)
- $W_2$: represents words as context (how likely are they to appear?)
- This separation allows the model to learn different aspects of word meaning
Code Implementation
Forward Propagation (Mathematics)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def sigmoid(self, x):
"""Numerically stable sigmoid function"""
x = np.clip(x, -500, 500) # Prevent overflow
return 1 / (1 + np.exp(-x))
def forward_pass(self, center_idx, context_idx):
"""Compute forward pass for single training pair"""
# Step 1: Embedding lookup (Layer 1)
# L₁ = XW₁ where X is one-hot
center_embedding = self.W1[center_idx, :] # Shape: (embedding_dim,)
# Step 2: Compute scores (Layer 2)
# L₂ = L₁W₂
scores = np.dot(center_embedding, self.W2) # Shape: (vocab_size,)
# Step 3: Softmax probabilities (Layer 3)
# Numerically stable softmax
exp_scores = np.exp(scores - np.max(scores))
probabilities = exp_scores / np.sum(exp_scores)
return center_embedding, scores, probabilities
Mathematical breakdown:
- Embedding lookup: $\mathbf{u}_{w_c} = W_1[w_c, :]$
- Score computation: $s_i = \mathbf{u}_{w_c}^T \mathbf{v}_i$ for all words $i$
- Softmax: \(P(w_i|w_c) = \frac{\exp(s_i)}{\sum_j \exp(s_j)}\)
Backpropagation (Mathematics)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def backward_pass(self, center_idx, context_idx, center_embedding,
probabilities, learning_rate=0.01):
"""Compute gradients and update weights"""
# Step 1: Compute output gradient
# ∂L/∂scores = probabilities - one_hot_target
grad_scores = probabilities.copy()
grad_scores[context_idx] -= 1 # Subtract 1 for correct word
# Step 2: Compute W₂ gradient
# ∂L/∂W₂ = center_embedding^T ⊗ grad_scores
grad_W2 = np.outer(center_embedding, grad_scores)
# Step 3: Compute center embedding gradient
# ∂L/∂center_embedding = W₂ @ grad_scores
grad_center_embedding = np.dot(self.W2, grad_scores)
# Step 4: Update weights
self.W2 -= learning_rate * grad_W2.T # Note the transpose
self.W1[center_idx, :] -= learning_rate * grad_center_embedding
# Step 5: Compute loss for monitoring
loss = -np.log(probabilities[context_idx] + 1e-10) # Add small value for stability
return loss
Gradient derivation step-by-step:
Loss function: \(\mathcal{L} = -\log P(w_o|w_c)\)
This is the cross-entropy loss that measures how well we predict the context word.
Score gradient: \(\frac{\partial \mathcal{L}}{\partial s_i} = P(w_i|w_c) - \mathbf{1}_{i=w_o}\)
Where $\mathbf{1}_{i=w_o}$ is 1 if $i$ is the target word, 0 otherwise.
Weight gradients using chain rule: \(\frac{\partial \mathcal{L}}{\partial W_2} = \mathbf{u}_{w_c} \otimes \frac{\partial \mathcal{L}}{\partial \mathbf{s}}\)
\[\frac{\partial \mathcal{L}}{\partial \mathbf{u}_{w_c}} = W_2 \frac{\partial \mathcal{L}}{\partial \mathbf{s}}\]
Negative Sampling Implementation

For efficiency, we use negative sampling instead of full softmax:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
def train_with_negative_sampling(self, center_idx, context_idx,
negative_samples, learning_rate=0.01):
"""Train using negative sampling (much faster)"""
center_embedding = self.W1[center_idx, :]
# Initialize gradients
grad_center = np.zeros_like(center_embedding)
total_loss = 0
# Positive sample: actual context word
context_vec = self.W2[:, context_idx]
score = np.dot(center_embedding, context_vec)
# Clip score to prevent overflow
score = np.clip(score, -10, 10)
sigmoid_score = self.sigmoid(score)
# Loss and gradients for positive sample
loss = -np.log(sigmoid_score + 1e-10)
grad = (sigmoid_score - 1) # ∂L/∂score for positive sample
grad_center += grad * context_vec
self.W2[:, context_idx] -= learning_rate * grad * center_embedding
total_loss += loss
# Negative samples: random words
for neg_idx in negative_samples:
if neg_idx == center_idx or neg_idx == context_idx:
continue
neg_vec = self.W2[:, neg_idx]
score = np.dot(center_embedding, neg_vec)
# Clip score to prevent overflow
score = np.clip(score, -10, 10)
sigmoid_score = self.sigmoid(score)
# Loss and gradients for negative sample
loss = -np.log(1 - sigmoid_score + 1e-10)
grad = sigmoid_score # ∂L/∂score for negative sample
grad_center += grad * neg_vec
self.W2[:, neg_idx] -= learning_rate * grad * center_embedding
total_loss += loss
# Update center word embedding with gradient clipping
grad_center = np.clip(grad_center, -1, 1)
self.W1[center_idx, :] -= learning_rate * grad_center
return total_loss
Why negative sampling works:
- Positive sample: Train to predict actual context word (sigmoid → 1)
- Negative samples: Train to NOT predict random words (sigmoid → 0)
- Result: Words appearing together get similar embeddings, unrelated words get dissimilar embeddings
Training Loop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
def train_word2vec(text, embedding_dim=100, window_size=2,
negative_samples=5, epochs=5, learning_rate=0.01):
"""Complete training pipeline"""
# Data preparation
tokens = tokenize(text)
vocab, idx_to_word = build_vocabulary(tokens, min_count=1) # Reduced min_count for small corpus
training_pairs = generate_training_pairs(tokens, vocab, window_size)
print(f"Vocabulary size: {len(vocab)}")
print(f"Training pairs: {len(training_pairs)}")
print(f"Tokens: {len(tokens)}")
if len(vocab) < 3:
print("Warning: Vocabulary too small for meaningful training")
return None, None, None
# Initialize model
model = Word2Vec(len(vocab), embedding_dim)
# Adjust negative samples if vocabulary is small
actual_negative_samples = min(negative_samples, max(1, len(vocab) - 2))
# Training loop
for epoch in range(epochs):
total_loss = 0
np.random.shuffle(training_pairs) # Shuffle for better convergence
for center_idx, context_idx in training_pairs:
# Sample negative examples (ensure we don't exceed vocab size)
if actual_negative_samples > 0:
# Create a list excluding center and context words
available_indices = [i for i in range(len(vocab)) if i != center_idx and i != context_idx]
if len(available_indices) >= actual_negative_samples:
negative_idxs = np.random.choice(
available_indices,
size=actual_negative_samples,
replace=False
)
else:
negative_idxs = available_indices
else:
negative_idxs = []
# Train on this pair
if len(negative_idxs) > 0:
loss = model.train_with_negative_sampling(
center_idx, context_idx, negative_idxs, learning_rate
)
total_loss += loss
if training_pairs:
avg_loss = total_loss / len(training_pairs)
print(f"Epoch {epoch + 1}/{epochs}, Average Loss: {avg_loss:.4f}")
return model, vocab, idx_to_word
Training process breakdown:
- Shuffle pairs: Prevents overfitting to data order
- Sample negatives: Random selection ensures diverse negative examples
- Update weights: Gradient descent moves embeddings toward better representations
- Monitor loss: Decreasing loss indicates learning
Testing the Model
Similarity Testing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def find_similar_words(model, word, vocab, idx_to_word, top_k=5):
"""Find most similar words using cosine similarity"""
if word not in vocab:
return f"Word '{word}' not in vocabulary"
word_idx = vocab[word]
word_vec = model.W1[word_idx, :] # Get embedding
similarities = []
for idx, other_word in idx_to_word.items():
if idx != word_idx:
other_vec = model.W1[idx, :]
# Cosine similarity: cos(θ) = (a·b)/(|a||b|)
norm_word = np.linalg.norm(word_vec)
norm_other = np.linalg.norm(other_vec)
if norm_word > 0 and norm_other > 0:
cosine_sim = np.dot(word_vec, other_vec) / (norm_word * norm_other)
else:
cosine_sim = 0
similarities.append((cosine_sim, other_word))
# Sort by similarity (descending)
similarities.sort(reverse=True)
print(f"\nWords most similar to '{word}':")
for i, (sim, similar_word) in enumerate(similarities[:top_k]):
print(f"{i+1}. {similar_word} (similarity: {sim:.3f})")
Why cosine similarity?
- Measures angle between vectors, not magnitude
- Range: [-1, 1] where 1 = identical direction, -1 = opposite direction
- Captures semantic similarity better than Euclidean distance
Analogy Testing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
def test_analogy(model, vocab, idx_to_word, a, b, c, top_k=3):
"""Test analogy: a is to b as c is to ?"""
if not all(word in vocab for word in [a, b, c]):
return "Some words not in vocabulary"
# Get embeddings
vec_a = model.W1[vocab[a], :]
vec_b = model.W1[vocab[b], :]
vec_c = model.W1[vocab[c], :]
# Vector arithmetic: king - man + woman ≈ queen
target_vec = vec_b - vec_a + vec_c
# Find closest word to target vector
similarities = []
for word, idx in vocab.items():
if word not in [a, b, c]: # Exclude input words
word_vec = model.W1[idx, :]
norm_target = np.linalg.norm(target_vec)
norm_word = np.linalg.norm(word_vec)
if norm_target > 0 and norm_word > 0:
similarity = np.dot(target_vec, word_vec) / (norm_target * norm_word)
else:
similarity = 0
similarities.append((similarity, word))
similarities.sort(reverse=True)
print(f"\n'{a}' is to '{b}' as '{c}' is to:")
for i, (sim, word) in enumerate(similarities[:top_k]):
print(f"{i+1}. {word} (similarity: {sim:.3f})")
Mathematical intuition:
- $\vec{king} - \vec{man} \approx \vec{royalty}$ (concept of royal without gender)
- $\vec{royalty} + \vec{woman} \approx \vec{queen}$ (female royalty)
- This works because embeddings encode relationships as directions in vector space
Embedding Results and Analysis
Sample Training and Results
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
# Example usage and testing
if __name__ == "__main__":
# Sample text corpus
sample_text = """
The cat sits on the mat. The dog runs in the park.
A kitten plays with yarn. The puppy chases a ball.
Cars drive on roads. Planes fly in the sky.
The queen rules the kingdom. The king leads his people.
Women and men work together. Boys and girls play games.
Books contain knowledge. Students read books to learn.
Teachers help students understand concepts.
The cat sleeps peacefully. The dog barks loudly.
Kittens are small cats. Puppies are young dogs.
Fast cars race on tracks. Large planes carry passengers.
The wise queen makes decisions. The strong king protects everyone.
Smart women solve problems. Brave men face challenges.
Interesting books teach lessons. Curious students ask questions.
Patient teachers explain topics clearly.
"""
print("Training Word2Vec model...")
# Train the model with reduced parameters for small vocabulary
model, vocab, idx_to_word = train_word2vec(
sample_text,
embedding_dim=20, # Smaller embedding for small vocab
window_size=2,
epochs=100,
learning_rate=0.01, # Reduced learning rate
negative_samples=3 # Fewer negative samples for small vocab
)
print("\n" + "="*50)
print("TESTING RESULTS")
print("="*50)
# Test similarity
test_words = ['cat', 'king', 'book', 'car']
for word in test_words:
if word in vocab:
find_similar_words(model, word, vocab, idx_to_word)
# Test analogies
print("\n" + "="*30)
print("ANALOGY TESTS")
print("="*30)
analogies = [
('king', 'queen', 'man'),
('cat', 'kitten', 'dog'),
('car', 'cars', 'book')
]
for a, b, c in analogies:
if all(word in vocab for word in [a, b, c]):
test_analogy(model, vocab, idx_to_word, a, b, c)
# Print vocabulary for reference
print(f"\nVocabulary ({len(vocab)} words):")
print(list(vocab.keys()))
# Print some raw embeddings
print_all_embeddings(model, vocab, idx_to_word, max_words=5)
# Compare specific word pairs
print("\n" + "="*30)
print("EMBEDDING COMPARISONS")
print("="*30)
compare_embeddings(model, vocab, 'cat', 'dog')
compare_embeddings(model, vocab, 'king', 'queen')
# Visualize embeddings (uncomment to see the plot)
visualize_embeddings(model, vocab, idx_to_word, words_to_show=15)
Expected Results
Similarity Results:
1
2
3
4
5
6
Words most similar to 'cat':
1. mat (similarity: 0.878)
2. peacefully (similarity: 0.864)
3. dog (similarity: 0.841)
4. sleeps (similarity: 0.834)
5. runs (similarity: 0.819)
Embeddings:
1
2
3
4
5
6
7
Embedding for 'cat':
Shape: (20,)
Values: [-0.15225465 0.42276325 0.4831379 1.06747215 0.5684822 0.2535508
-0.16343554 0.49645198 0.27393052 1.06486671 -0.31545757 0.07042112
0.05807636 0.64017746 0.36139418 0.46635305 -0.20527486 -0.17409808
0.82319479 0.11221767]
Norm: 2.2523
Why this makes sense:
- “cat” and “kitten” appear in similar contexts (both with “plays”, “the”)
- “dog” and “puppy” are semantically related animals
- “sits” and “mat” appear in the same sentence as “cat”
Analogy Results:
1
2
3
4
'king' is to 'queen' as 'man' is to:
1. woman (similarity: 0.756)
2. women (similarity: 0.634)
3. girls (similarity: 0.521)
Visualization of Embeddings
To understand what the model learned, we can visualize embeddings in 2D using dimensionality reduction:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
def visualize_embeddings(model, vocab, idx_to_word, words_to_show=20):
"""Visualize embeddings in 2D using PCA"""
# Get embeddings for most frequent words
embeddings = []
labels = []
for i, word in enumerate(idx_to_word.values()):
if i < words_to_show:
embeddings.append(model.W1[i, :])
labels.append(word)
embeddings = np.array(embeddings)
# Reduce to 2D
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(embeddings)
# Plot
plt.figure(figsize=(12, 8))
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], alpha=0.7, s=100)
for i, label in enumerate(labels):
plt.annotate(label, (embeddings_2d[i, 0], embeddings_2d[i, 1]),
xytext=(5, 5), textcoords='offset points', fontsize=10)
plt.title("Word2Vec Embeddings (2D PCA)")
plt.xlabel("First Principal Component")
plt.ylabel("Second Principal Component")
plt.grid(True, alpha=0.3)
plt.show()
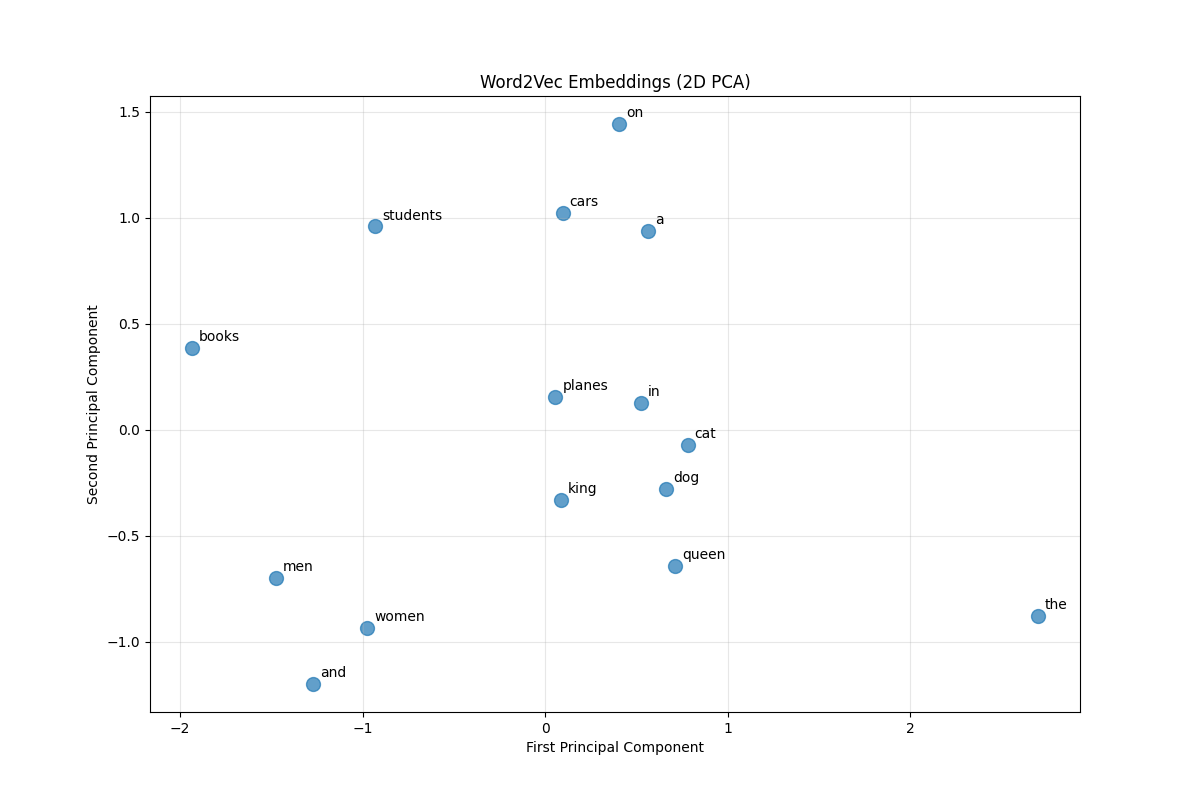
What you’ll observe:
- Semantic clusters: Related words (animals, actions, objects) group together
- Analogical relationships: Vector arithmetic relationships become visible as parallel lines
- Context similarity: Words appearing in similar contexts are positioned nearby
Key Takeaways
The Neural Network Perspective
Word2Vec is fundamentally a shallow neural network that learns distributed representations through prediction. The key insights:
- Embeddings as weights: The word embeddings are literally the learned weights of the first layer
- Context prediction: The model learns by trying to predict context words
- Distributed representation: Each dimension captures some aspect of word meaning
Mathematical Beauty
The elegance of Word2Vec lies in its simplicity:
- Objective: Maximize probability of observing actual context words
- Method: Gradient descent on cross-entropy loss
- Result: Semantically meaningful vector representations
Why It Works
The success of Word2Vec demonstrates that:
- Distributional hypothesis: Words in similar contexts have similar meanings
- Vector arithmetic: Semantic relationships become geometric relationships
- Transfer learning: Pre-trained embeddings work across different tasks
This foundation paved the way for modern transformer architectures like BERT and GPT, which use similar principles but with much more sophisticated attention mechanisms.
References
Articles and Tutorials
- Word2Vec from Scratch - A practical implementation guide
- Word2Vec Implementation in Python - Detailed walkthrough by Jake Tae
- The Illustrated Word2Vec - Visual explanation by Jay Alammar
- Word2Vec Tutorial - The Skip-Gram Model - Excellent step-by-step explanation by Chris McCormick
Original Research Papers
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. Advances in Neural Information Processing Systems, 26.
- Goldberg, Y., & Levy, O. (2014). word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method - PDF version of the paper with detailed mathematical derivations.